














In this post, we’re going to talk about the way that Git labels and refers to its commits using hash values.
What Are Hash Values?
In the first place, to understand this subject matter, you must understand hash values. They are unique identifiers, often used in data structures like hash tables. When it comes to Git, hash values take on a special role. Git uses a specific type of hash value known as SHA-1.
SHA-1 stands for Secure Hash Algorithm 1. It’s a cryptographic hash function that takes an input and produces a 160-bit (20-byte) hash value. This hash value is a unique representation of the input data.
In Git, every commit you make is assigned a unique SHA-1 hash value. This hash value is like a fingerprint for each commit. It helps Git keep track of every change made in the repository.
Remember, hash values in Git are crucial for maintaining the integrity of your projects. They ensure that your code history remains intact and unchanged.
How are Hash Values Used in Git?

Every time you commit changes, Git generates a unique hash value. This value is a SHA-1 hash of the commit’s contents, including its code changes and metadata.
Think of these hash values as unique IDs. They allow Git to track each commit individually. This tracking is what enables Git’s powerful version control capabilities.
But it’s not just commits that get hash values. Git also assigns them to other objects like trees and blobs. A tree in Git is a snapshot of your project’s directory structure. Blobs, on the other hand, represent the actual file data.
So, in essence, hash values are the backbone of Git’s data model. They link commits, trees, and blobs together to form a coherent history of your project.
The Comprehensive Workings of Hash Values (SHA-1) in Git
In this section, having gotten acquainted with the basics, let us delve deeper into the workings of hash values in Git. In the previous post about Git Architecture, we talked about the typical Git workflow and changes moved from our working directory to our staging index, into our repository. We had called these simply A, B, and C. They represented different changesets.
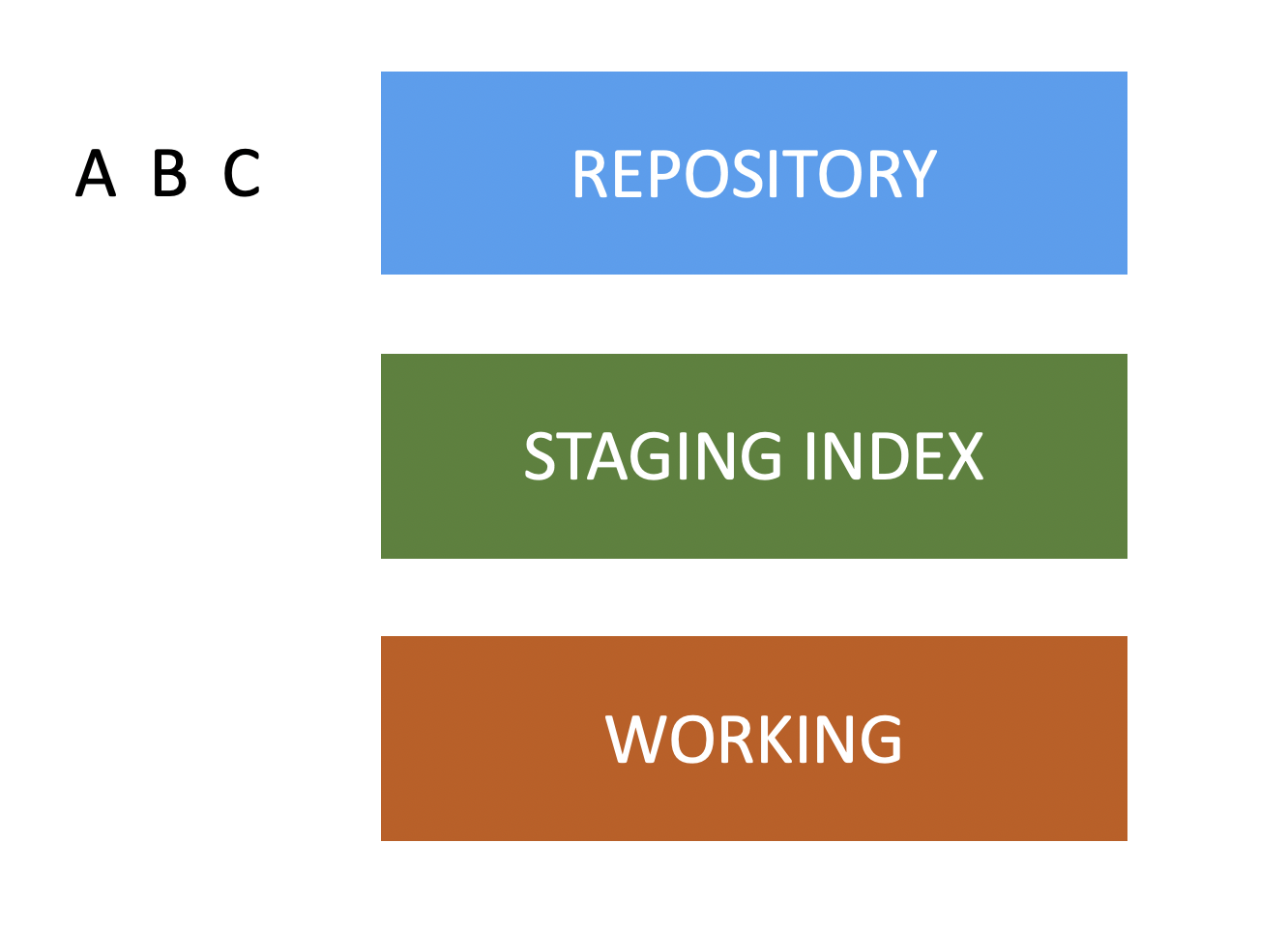
In the simple example here, they represented changes to only a single file, but in real usage, this could be changed to multiple files and directories, all packaged together into a single snapshot. It’s a snapshot of changes to our project.
Recommended reading: Head pointer in GIT: What You Need To Know?
We called them A, B, and C just to keep it simple, but that’s not the way that Git refers to them. Instead of that, Git generates something called a checksum for each of the changesets. That’s the hash value.
According to Wiki:
In cryptography, SHA-1 (Secure Hash Algorithm 1) is a cryptographic hash function that takes an input and produces a 160-bit (20-byte) hash value known as a message digest – typically rendered as a hexadecimal number, 40 digits long. It was designed by the United States National Security Agency and is a United State. Federal Information Processing Standard.
A checksum is a simple number that’s created by taking data and feeding it into a mathematical algorithm. So the checksum algorithm converts data into a simple number and we call that simple number a checksum. GIT very strongly relies on SHA-1 for the identification and integrity checking of all file objects and commits. It is possible to create 2 GIT repositories with the same commit hash and different contents (which could be backdoored).

Recommended reading: What Is Git and How Does Git Track Our Project Files?
Attackers could potentially selectively serve either repository to targeted users. This will require attackers to calculate their own collision. This attack required over 9,223,372,036,854,775,808 SHA-1 computations. This means that it will take the equivalent processing power of approximately 6,500 years of single-CPU computations and about 110 years of single-GPU computations.
We don’t need to understand much about how the algorithms work, but we should know that there’s a fundamental property that’s very important. The same data put into the same mathematical algorithm always returns the same result or the same checksum. That’s why we call it a checksum because we can check and make sure that it’s the same. It’s used to guarantee data integrity, and data integrity’s fundamentally built into Git because of this. That’s not true of all version control systems.
The label that Git uses for each one of its snapshots of changes is fundamentally tied to what’s in those changes. If we were to change that information, then the label or hash value would change. So each hash value is not only unique, it’s directly tied to the contents that are inside of it. The algorithm that Git uses is the SHA-1 hash algorithm which basically is a cryptographic hash function taking input and producing a 160-bit (20-byte) hash value. We don’t need to know anything about SHA-1 or how it compares to other algorithms that are out there, but we do need to know its name because it’s frequently used.
FURTHER READING: |
1. What Are Git Concepts and Architecture? |
2. .gitignore: How Does it Work? |
3. What Is Git And How Does Git Track Our Project Files? |
People will refer to this value as being the SHA value or the S-H-A value. So if we hear someone say, what’s the SHA value of that commit? That’s what they’re referring to. It’s the hash value that’s used to label each one of the commits. The number that it generates is a 40-character hexadecimal string. Hexadecimal means that it can contain the numbers zero through nine and the letters A through F, and it would look something like this, 5c15e8bd, and so on.
So Git takes the entire changeset to all the files and directories that are being changed, things that have been staged, and it runs them through this SHA-1 algorithm and it comes up with this 40-long character string. And that’s what it uses to label the commit. Not only does Git do that with our changeset, but it also does something else important for data integrity.
In addition to using the code that’s in each one of our snapshots, it also uses the metadata as well. It means that you can’t change the commit message or the commit author or the parent of the commit without also changing its SHA value. That gives us a nice chain of data integrity because when it goes to generate snapshot A, it takes the parent, the author, the message, and all the code changes, and it generates its SHA value.
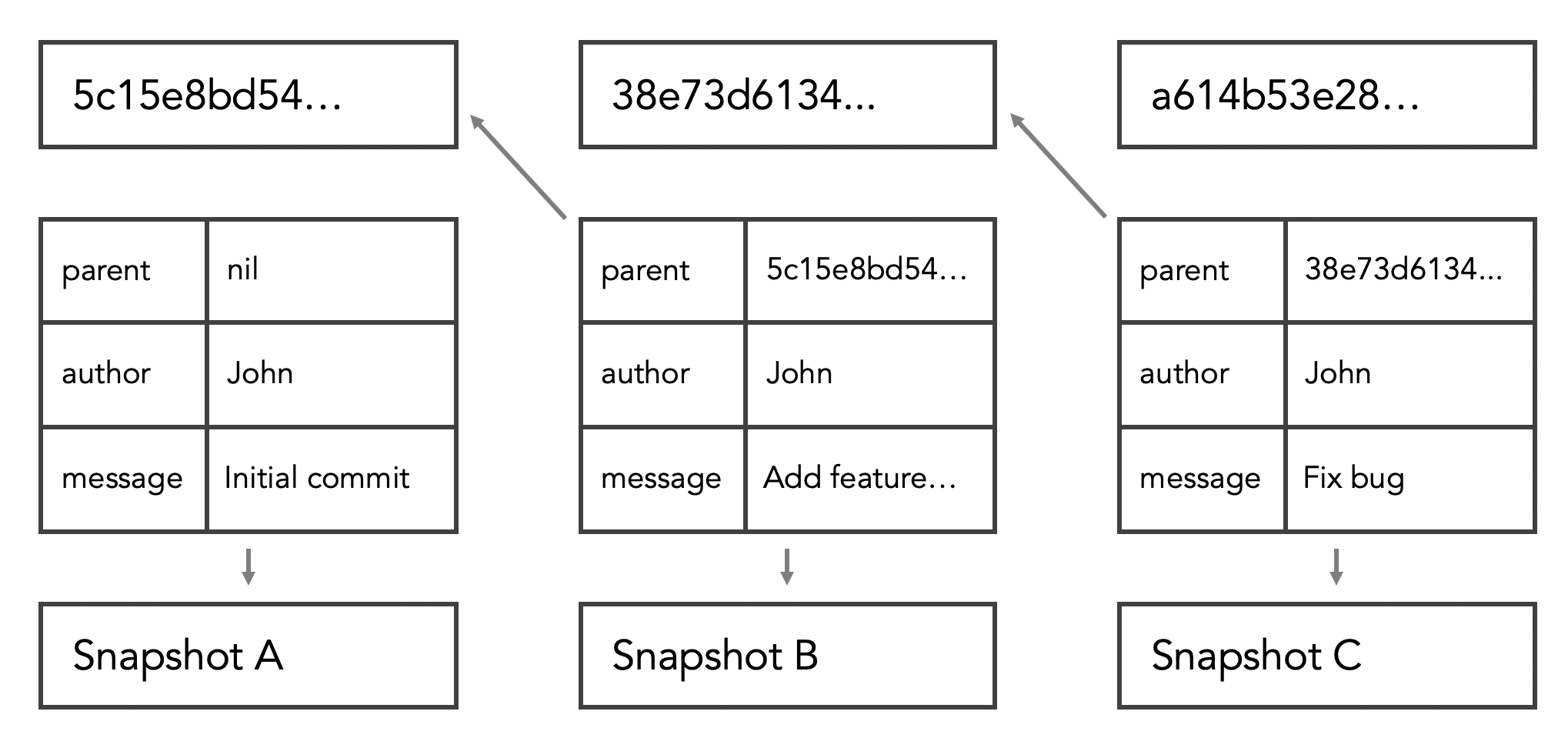
Then when we make snapshot B, snapshot B also goes through that same process, but it includes the SHA value from snapshot A, so it’s linked to A. If we were to change something in A, then A’s SHA value would change and B won’t point to it anymore. One of the really nice features of Git is the fact that the data integrity of not only our changesets but also the history of changes and how they relate to each other is built-in.
To summarize what we have discussed so far:
- Git generates a checksum for each of the changesets (Hash value)
- The checksum algorithm converts data into a simple number (called a Checksum)
- Same data always equals the same checksum
- Data integrity is fundamental
- Changing data would change the checksum
- Git uses the SHA-1 hash algorithm to create checksums
Designveloper hopes that this post is valuable to you. Have a nice day my friends!
Also published on

Share post on










Read more topics

























