














In 2020, the total amount of data we created, consumed, and copied reached 64.2 zettabytes. However, only a handful (2% exactly) was stored and managed. As the global data creation will to mushroom to over 180 zettabytes in 2025, one big question arises: how can we organize and store this massive data for faster access, modification, and usage? The answer lies in data structures. So, what is data structure, and how can it help manage data effectively? Let’s find it out!
What is Data Structure?

“A data structure is a way of organizing data in some fashion so that later on, it can be accessed, queried, or even updated easily and quickly”
It is a collection of values. The values can have relationships among them and they can have functions applied to them. Besides, each one is different in what it can do and what it is best used for.
They are essential components in creating fast and powerful algorithms. They help to manage and organize data so that it will make our code cleaner and easier to understand. In other words, data structures can make the difference between an Okay product and an outstanding one.
What is Abstract Data Type (ADT)?
Before getting to data structures, we have to talk about their abstraction first, often known as Abstract Data Types (ADTs).
An abstract data type (ADT) is simply an abstraction of a data structure. It provides a foundation which data structures should adhere to. The foundation only defines what a data structure should do (e.g., adding and eliminating elements), but not specify how it should implement that functionality or what programming language to use for the implementation.
ADTs are “abstract” because they are just theoretical concepts and every programming language has different ways of implementing it.
Recommended reading: Tree Data Structure: A Closer Look
Classification of Data Structures
Data structures are often categorized into two key groups: Linear and Non-linear. Now, let’s discover each data structure and its applications:
Linear Data Structure
In a linear data structure, data elements are organized in a linear sequence, one after the other. In other words, each element is connected to its previous and next adjacent elements in a single order.
This makes it simple to access, add, or remove the elements in a consistent, orderly way. Accordingly, the first added element is the first one accessed or eliminated, while the last added element is the last one accessed or deleted.
With this capability, linear data structures are ideal for various programming tasks that need to handle data in a specific order, like processing to-do lists or triggering Undo features in text editors.
Linear data structures have two memory sizes:
- Static: This type of data structure has a fixed size. It means you can’t increase or decrease a structure’s size flexibly once the structure is created.
- Dynamic: This type of data structure can grow or shrink when you add or remove elements.
Below are four popular linear data structures:
Array
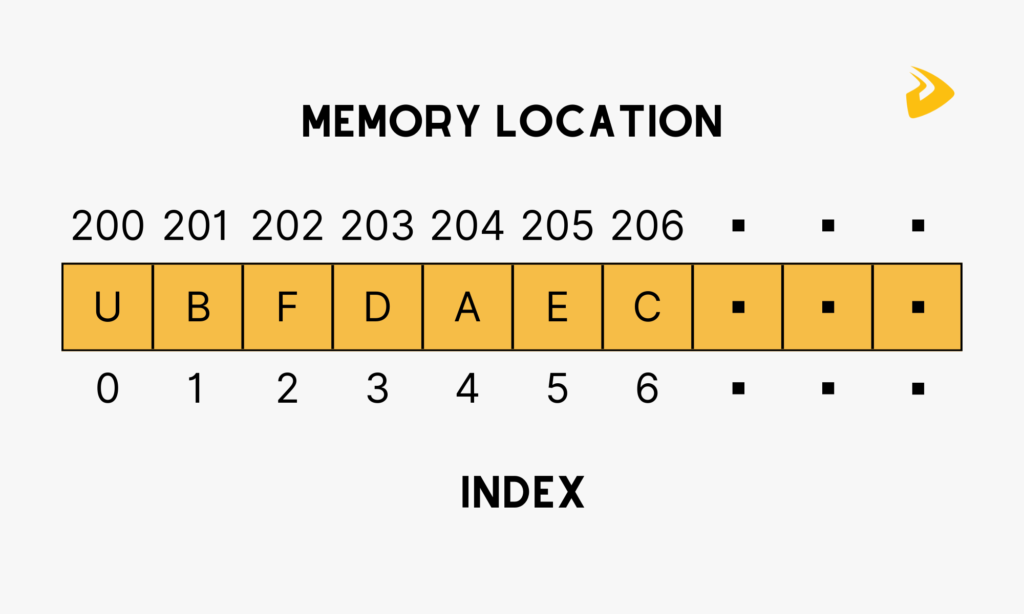
A static array is a fixed-length container containing n elements indexable from the range [0, n-1]. Indexable means that each slot/index in the array can be referenced with a number called index key (typically zero-based). This allows random access to any array element. Static arrays are given as contiguous chunks of memory.
The name assigned to an array is typically a pointer to the first item in the array. It means that given an array named myArray which was assigned the value [‘a’, ‘b’, ‘c’, ‘d’, ‘e’], in order to access the ‘c’ element, we would use the index 2 to lookup the value (myArray[2]).
Arrays are traditionally ‘finite’ in size, means that we define their length/size (i.e. memory capacity) in advance, but there is a concept known as ‘dynamic arrays’ (and of which you’re likely more familiar with when dealing with certain high-level programming languages) which supports the growing (or resizing) of an array to allow for adding more elements to it. But under the hook, the new array (normally with double size compared to the original) is created in order to copy the original array element values over to.
Applications of Array
- Serve as the primitive building blocks to build other data structures such as array lists, heaps, hash tables, vectors and matrices.
- Used for different sorting algorithms (insertion sort, quick sort, bubble sort and merge sort..).
Recommended reading: What Is Big Data Analytics and How It Useful for Business?
Linked List
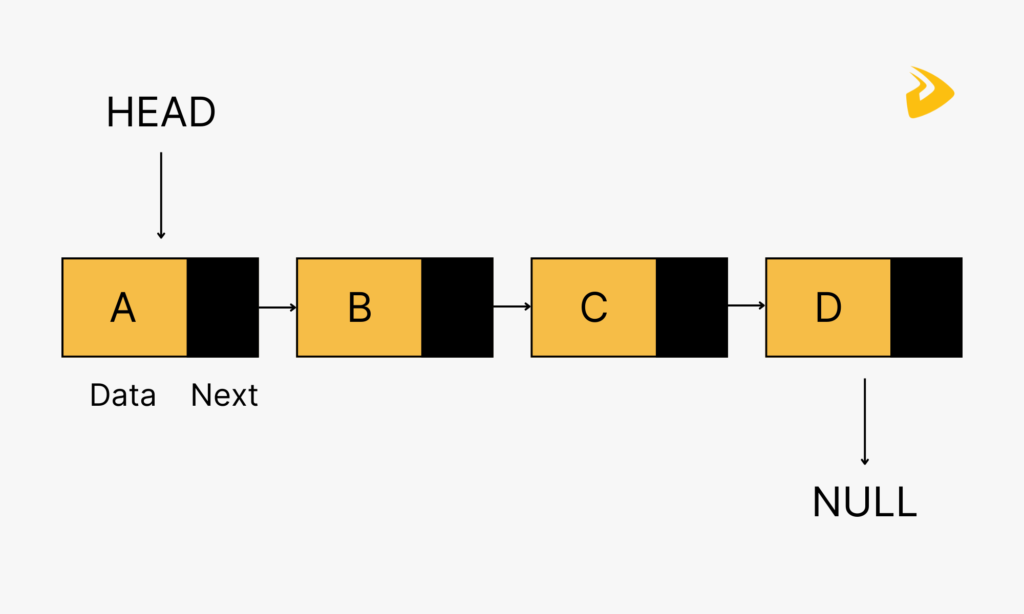
A linked list is different from an array in the order of the elements within the list that is not determined by contiguous memory allocation. Instead, the elements of the linked list can be sporadically placed in memory due to its design. It means each element (a ‘node’) consists of two parts:
- The data is what we’ve assigned to that element/node.
- A pointer is a memory address reference to the next node in the list.
Unlike an array, there is no index access. So in order to locate a specific piece of data or element we will have to traverse the entire list until we find the element we’re looking for. That operation takes O(n) complexity.
This is one of the key performance characteristics of a linked list and is why (for most implementations of this data structure) we’re not able to append data/element to the list (because talking about the performance of such an operation, it would require us to traverse the entire list to find the end/last node). Instead linked lists generally will only allow prepending to a list as it’s much faster. The newly added node will then have its pointer set to the original ‘head’ of the list.
There is also a modified version of this data structure called ‘doubly linked list’ which is essentially the same idea but with the exception of the third attribute for each node: a pointer to the previous node (in a normal linked list we only have a pointer to the following node).
Applications of Linked Lists
- Helpful for symbol table management in a designing compiler.
- Used in switching between applications and programs in the Operating system (implemented using Circular Linked List).
| FURTHER READING: |
| 1. What is Big O Notation? |
| 2. Top Blockchain Companies in 2022 |
| 3. Hash Values (SHA-1) in Git: What You Need To Know |
Queue
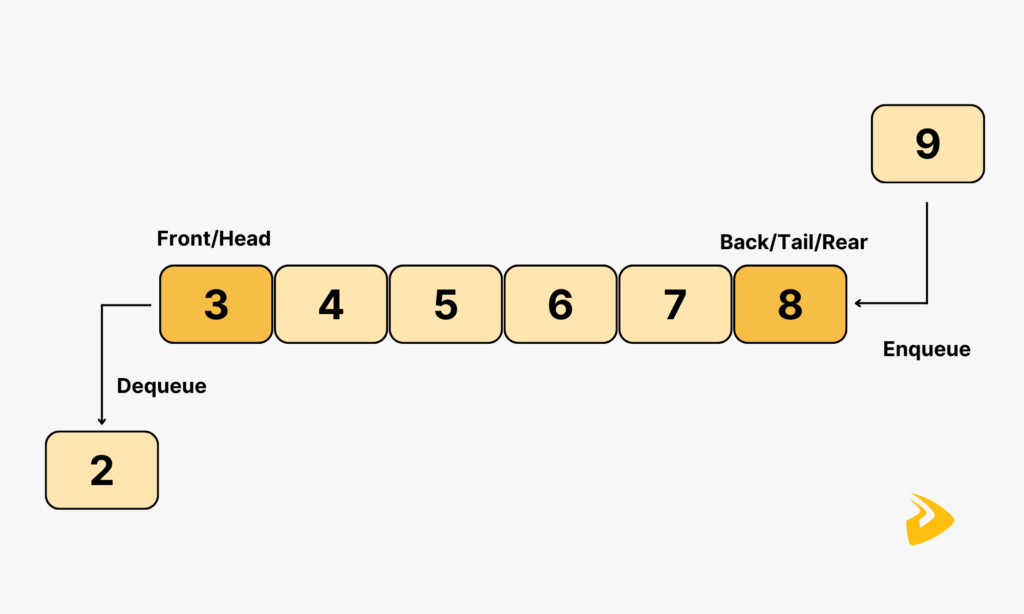
A queue data structure works in accordance with the FIFO (First In, First Out) principle. This means the first element that enters a queue will be the first one to leave. Further, the position where to add the first element is often known as the front (head) of the queue, while the position of the last element added is called the rear (tail) of the queue.
The way queue data structures operate is very straightforward:
- Enqueue: Insert a data element to a queue’s rear.
- Dequeue: Remove the element from the queue’s head.
- Peek or Front: Check the element at the head of the queue without removing it.
- Rear: Check the element at the tail of the queue without removing it.
- isFull: See whether the queue is full. It’ll return “true” if the queue has no more space to add new elements.
- isEmpty: See if the queue is empty. If the queue has no elements, it’ll return “true.”
There are different types of queues. A simple queue simply follows the FIFO principles. Meanwhile, a double-ended queue can insert and delete elements from both ends of a queue. A circular queue allows the last entry anchoring to the first one, while a priority queue allows you to access elements based on their assigned priorities.
Applications of Queue
- Used for job scheduling like printer spooling (which means placing numerous print tasks sent to a printer in a queue).
- Ideal for managing requests from various consumers (e.g., users or programs) accessing a single resource (e.g., a CPU or printer).
- Help network devices (e.g., routers or switches) and mail servers process data packets and emails in order.
- Support some algorithms like Breadth-First Search (BFS) or Topological Sort.
Stack
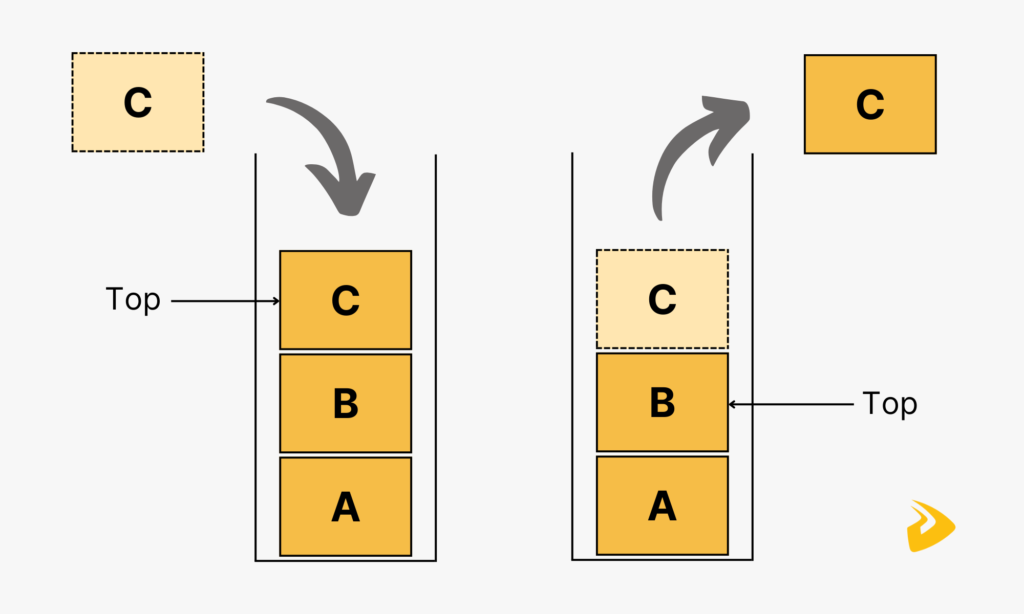
A stack data structure relies on the LIFO (Last In First Out) principle. This means you can add a new data and remove an existing element only from the top of a stack.
There are two types of stack data structures: Fixed and Dynamic. The former has a predefined maximum size. If you add more elements than the stack can hold, this will lead to an overflow error. On the contrary, if you try to delete an element from an empty stack, this will trigger an underflow error. This type of stack often uses an array for execution.
A dynamic size stack, on the other hand, can grow or shrink depending on the insertion or deletion of data. It commonly uses linked lists for implementation as this data structure enables you to add or remove elements at any points. This makes it ideal for resizing the stack.
Regardless of stack sizes, they work based on the following basic steps:
- Push: You add an element to the top of a stack.
- Pop: You then remove the topmost element from the stack.
- Top: The top operation allows you to check the value of the topmost element without deleting it.
- isEmpty: You will look at whether there are any elements left in the stack. If yes, it’ll return “true.”
- isFull: You will look at whether the stack is full and can’t store any more elements. If it reaches its maximum capacity, it’ll return “true.”
Applications of Stack
- Helpful in converting mathematical expressions from infix (standard arithmetic) to postfix/prefix.
- Manage undo/redo actions in text or image editors (like Microsoft Word or Photoshop).
- Track navigation (forward/backward) in web browsers.
- Organize memory for running programs to track function calls and local variables.
Non-Linear Data Structure
As the name states, this type of data structure doesn’t place data elements in a linear sequence, which means you can’t go through all the elements in a single run only. Two popular non-linear data structures include Tree and Graph.
Tree
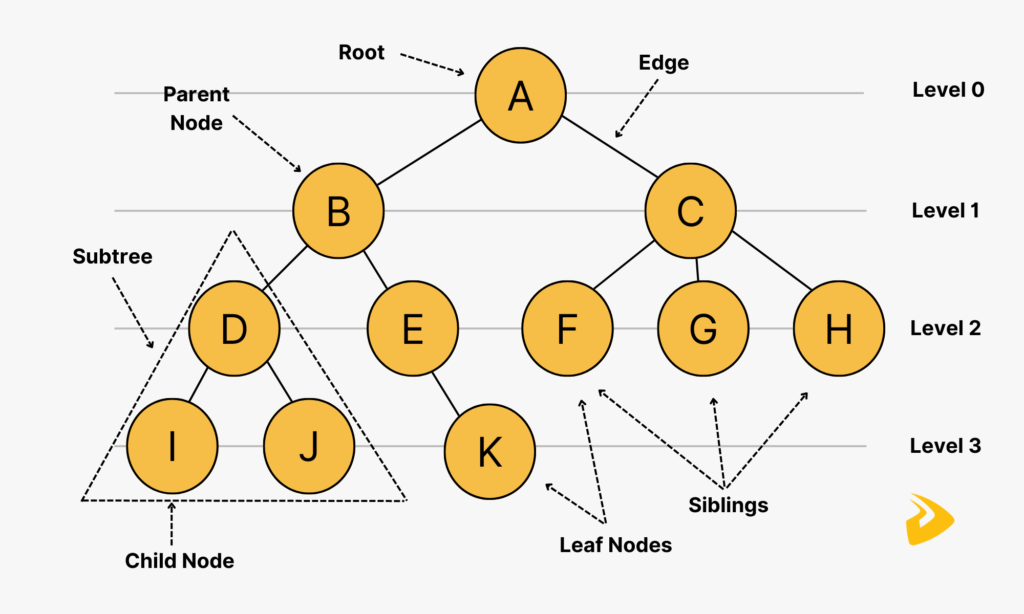
A tree is a hierarchical structure where data is organized hierarchically and are connected together. This structure is different from a linked list whereas, in a linked list, items are linked in a linear order.
A tree contains “nodes” (a node has a value associated with it) and each node is connected by a line called an “edge”. These lines represent the relationship between the nodes.
Recommended reading: Stacks and Queues in Data Structures: An Overview
Additionally, the top-level node is known as the “root” and a node with no children is a “leaf”. If a node is connected to other nodes, then the preceding node is referred to as the “parent”, and nodes following it are “child” nodes.
There are various incarnations of the basic tree structure, each with their own unique characteristics and performance considerations:
- Binary Tree
- Binary Search Tree
- Red-Black Tree
- B-tree
- Weight-balanced Tree
- Heap
- Abstract Syntax Tree
Applications of Tree
- Used to implement database indexes (index is a structure that exists independent of the data in the database which improves the query optimizers’ ability to execute the query quickly. In other words, an index is something we create for a column in a table to speed up searches involving that column)
- Heaps data structure helps JVM (Java Virtual Machine) to store Java objects, while treap data structure is useful in wireless networking.
Graph
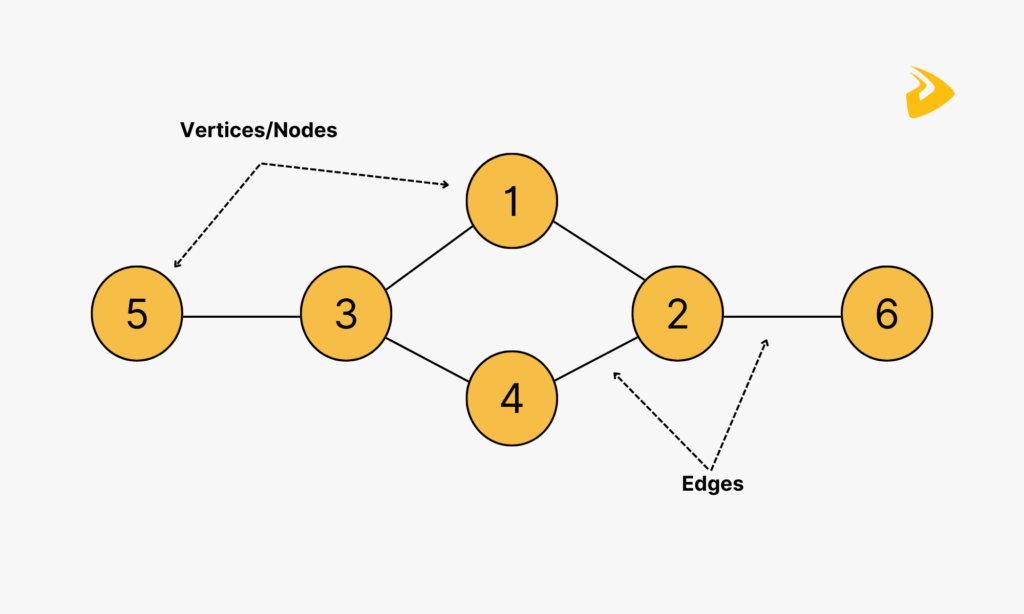
A graph often includes two components: vertices and edges. Particularly, the edges (“lines” or “arcs”) serve as a bridge that connects two vertices (“nodes” or “vertex”) in the graph. Besides, both the vertices and edges can be labeled or unlabeled. Normally, a graph has a range of vertices (V) and a range of edges (E), hence being denoted by G(V,E).
Graph data structures have different types, including:
- Null graph
- Trivital graph
- Undirected graph
- Directed graph
- Connected graph
- Disconnected graph
- Regular graph
- Complete graph
- Cycle graph
- Cyclic graph
- Directed acyclic graph
- Bipartite graph
- Weighted graph
Further, there are two common ways to represent and store a graph data structure: Adjacency Matrix and Adjacency List. The former is a 2D matrix (a table) that displays which vertices are connected to each other in a graph. Meanwhile, the latter is a list-based structure that indicates which vertice has a list of all adjacent vertices.
A graph works in accordance to the following basic operations:
- Add a new vertice or remove an existing one. The insertion and deletion of a node are slightly different across graph representations.
- Insert or remove edges. Similarly, the insertion and deletion of an edge vary across graph representations.
- Search for specific vertices or edges in the graph to see whether there are any entities or relationships.
- Traverse through each vertice to explore it further using methods like Depth-First Search (DFS) or Breadth-First Search (BFS)
Applications of Graph
- Useful for social network analysis, computer networks, neural networks, compilers, and robot planning.
- Help represent how different places (e.g., roads and airports) in a transportation network connect to each other.
- Visualize how tasks in a software project depend on the completion of other tasks.
Conclusion
This article showed what data structure is and its common types: Linear and Non-linear. Learning about these data structures helps you store, organize, and manage data effectively, which is crucial for processing vast amounts of data like databases. Further, choosing the right data structure helps improve a program’s performance and develop algorithms to handle different problems.
So, if you want to stay updated about this interesting topic, don’t forget to subscribe our blog and follow our social networking sites (Facebook, Twitter, LinkedIn)! 😉
Also published on

Share post on










Read more topics

























