













Large Language Models (LLMs): How to Fine-Tune Them to Reduce the Costs Associated
November 22, 2024

When you’re developing an AI-based app, you have a couple of options. You can start from scratch or take a shortcut by fine-tuning a large language model. Fine-tuning large language models involves adapting a pre-trained model to your specific needs, saving time and resources compared to building one from the ground up. Not sure what we’re talking about? If so, you’re probably better off hiring a reputable firm to make these decisions for you.
What are Large Language Models?
These computational models create text-based content. You can use them as a base for chatbots, translation software, and other content creation tasks. These models train on thousands of pages online, so they contain vast amounts of data.

If you’re developing an application, you can use LLMs as a foundation. You’ll simply have to feed in training data so it’s fit for purpose.
Think of it kind of like help desk outsourcing. You hire a team to get the professional customer support skills you need. In this case, however, the LLMs are giving your application the expertise it needs to start off.
FURTHER READING: |
1. 5 AI and Machine Learning Trends to Watch in 2025 |
2. Future of Machine Learning: Trends & Challenges |
3. What is Elon Musk’s AI Grok? Everything You Need to Know |
What are the Costs of Fine-Tuning LLMs
You’ll save money with this, but tweaking an LLM is still costly. You’ll need to consider:
- Computational Power: You’ll need high-performance hardware like GPUs or TPUs. These are not only expensive to buy but also to operate. You’ll also pay a fair amount for cloud-based alternatives like AWS or Azure.
- Data Preparation: You need relevant, high-quality data to train your model on. You’ll have to spend time collecting, cleaning, and annotating it. This is expensive and requires specialist knowledge.
- Storage and Bandwidth: You’ll need a lot of storage and bandwidth to handle large datasets and model files.
- Expertise: You’ll need skilled machine learning engineers and data scientists, who command high salaries.
- Energy Consumption: The computational processes use a lot of power, which comes at a high environmental and financial cost.
Before you run off screaming, it’s not as much of a horror story as it seems at first. You can reduce these expenses if you plan carefully.
FURTHER READING: |
1. Machine Learning vs AI: Understanding the Key Differences |
2. NLP and ML in Paraphrasing Tool: How Does It Work? |
Strategies to Reduce Fine-Tuning Costs
Now, let’s look how you can make the process more cost-effective without compromising quality.
1. Leverage Smaller, Efficient Models
LLMs are massive and can contain billions of parameters. Do you need that much information? Probably not, which is why you can save money by using a smaller, more efficient LLM. These use fewer computational resources and save you time.
2. Use Parameter-Efficient Fine-Tuning
With this technique you work with a subset of the LLM’s parameters. You choose those that are most relevant to you and leave the rest alone. Therefore, you won’t need as much storage or computing power.
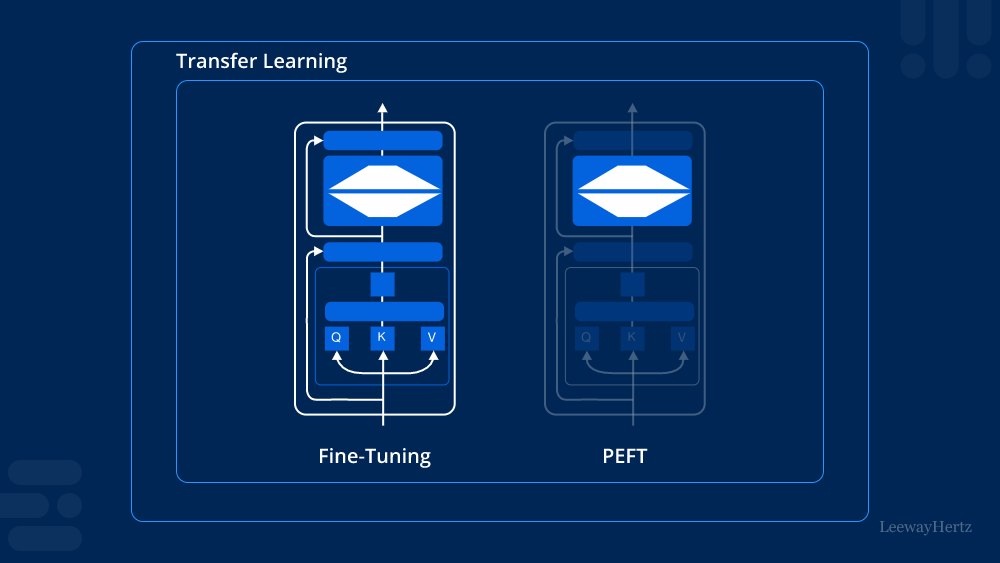
Some examples are:
- LoRA (Low-Rank Adaption): With this approach you update a small set of parameters, making fine-tuning faster.
- Adapters: Here you insert a lightweight module that will train only these aspects rather than the entire network.
3. Adopt Few-Shot or Zero-Shot Learning
With this technique, you scale down the training information.
With zero-shot learning, you rely on the model’s pre-trained knowledge. The downside of this approach is that the LLM may learn from variable datasets across the internet. Therefore, it may not always come up with the right solution. It’s not ideal for a company creating a chatbot to help customer support.
Few-shot learning is also more cost-effective because you use less training data. The key to getting this right is in choosing the best-quality examples you can find. The potential downside is that you might not account for edge cases, which can leave your app short
Planning for this can mean including some outliers so your model has a balanced education.
4. Optimize Training Data
If you’re studying medicine, do you learn from Dr Google or textbooks and peer-reviewed studies? Naturally, you choose reputable information sources and ignore much of what the internet says.
When you’re tweaking your LLM, you need high-quality data. This is more valuable than swathes of irrelevant rubbish. Therefore, spending time curating your data can reduce your costs significantly.
Here’s how to get a better-quality dataset:
- Remove Duplication: Start by getting rid of redundant entries.
- Use Domain-Specific Data: You should focus on the datasets that are most relevant to your needs.
- Downsample Wisely: You want to reduce the size of your dataset without compromising on key features or examples.
It takes a little more work upfront, but you’ll reap the rewards in reduced computing resources.
5. Leverage Cloud-Based Solutions Wisely
You can use platforms like Google Cloud, AWS, and Azure for scalable computing resources. These are pricey, but these tips can save you money:
- Use Spot Instances: Fine-tuning isn’t usually urgent, so you can save money by working when the network is less busy. The downside is that the work will take longer overall.
- Use Free Tiers: Do use the promotional credits cloud providers give you to entice you to join up,
- Go Regional: Find a cloud company with servers in lower-cost countries.
- Use Auto-Scaling: With this option, you don’t pay for resources you don’t use.
Should You Think About an In-House Solution?
If you’re going to run this type of project on an on-going basis, it may be more cost-effective to buy the hardware.
6. Use Pre-Fine-Tuned Models
You’ll still need to train your LLM to a certain extent, but not nearly as much as you would from scratch. You can easily find pre-trained models for things like:
- Sentiment analysis
- Summarization
- Medical diagnostics
These models don’t need many adjustments, which saves you time and money.
7. Optimize Computing Resources

You can use the following techniques:
- Gradient Checkpointing: You save memory by only storing selected intermediate outputs.
- Mixed Precision Training: You can use lower-precision calculations to reduce memory and power consumption without sacrificing accuracy.
- Batch Size Tuning: You can test different batch sizes to find the most cost-effective option.
Balancing Costs and Performance
Reducing costs doesn’t mean sacrificing performance. By carefully selecting tools, techniques, and workflows, you can achieve high-quality results without overspending. Start with the strategies that make the biggest impact—like using smaller models or parameter-efficient fine-tuning—and scale your approach as needed.
Fine-tuning Large Language Models doesn’t have to break the bank. With smart planning and the right resources, you can unlock the power of AI while staying on budget.
Also published on

Share post on










Read more topics

























