













Customer Segmentation Using Machine Learning for Beginners

Customer segmentation is the practice of classifying customers into groups based on shared factors. These factors involve demographics, buying habits, or interests. By grouping customers this way, your business can devise more targeted marketing campaigns. This can increase customer satisfaction and your overall business success as each group gets a message that fits their needs.
Previously, segmentation often depended on assumptions or manual implementation. This often resulted in inaccurate targeting as humans had to sift through vast volumes of customer data and might overlook crucial information. As a result, your company might lose potential customers or waste resources on ineffective marketing strategies.
This is where machine learning changes how we segment customers. So, what exactly is customer segmentation using machine learning? Let’s find it out with us in today’s article!
What is Machine Learning in Customer Segmentation?

Machine learning (ML) in customer segmentation involves using algorithms to analyze customer data and automatically group customers.
Unlike traditional segmentation methods that rely on basic demographic data, ML can gather diverse, complex data from different sources in a second. This data can range from demographics, purchase history, and online habits to customer interactions and feedback.
Using artificial intelligence algorithms and statistical models, ML can identify relevant characteristics or variables within a customer base and group customers accordingly. This allows for more accurate and dynamic segmentation.
Machine learning is no longer just an emerging trend. As more companies recognize its potential, ML continues to advance to meet a growing demand. Accordingly, its global value is estimated to increase by 36.08% annually from 2024 to 2030. This rapid growth promises even more advanced and personalized customer segmentation in the near future.
Common Algorithms for Customer Segmentation
We’ve mentioned the term “algorithms” as essential tools for machine learning to automate and accelerate customer segmentation. So what are they, exactly?
ML algorithms refer to a set of instructions or rules that guide computers to learn patterns from data and make data-driven decisions without much human intervention. As the backbone of ML systems, these algorithms can process data to look for patterns, correlations, or insights for various purposes like customer classification or predictions.
However, not all algorithms work the same. Different algorithms work best with different types of data. For instance, K-Means Clustering works well when data has clear groupings. Meanwhile, DBSCAN is a better fit for noisy data. Understanding different algorithms helps you pick the right one for your machine learning model and serve your ultimate purpose best.
Here, we’ll list several common machine-learning algorithms for customer segmentation:
1. Clustering Algorithms
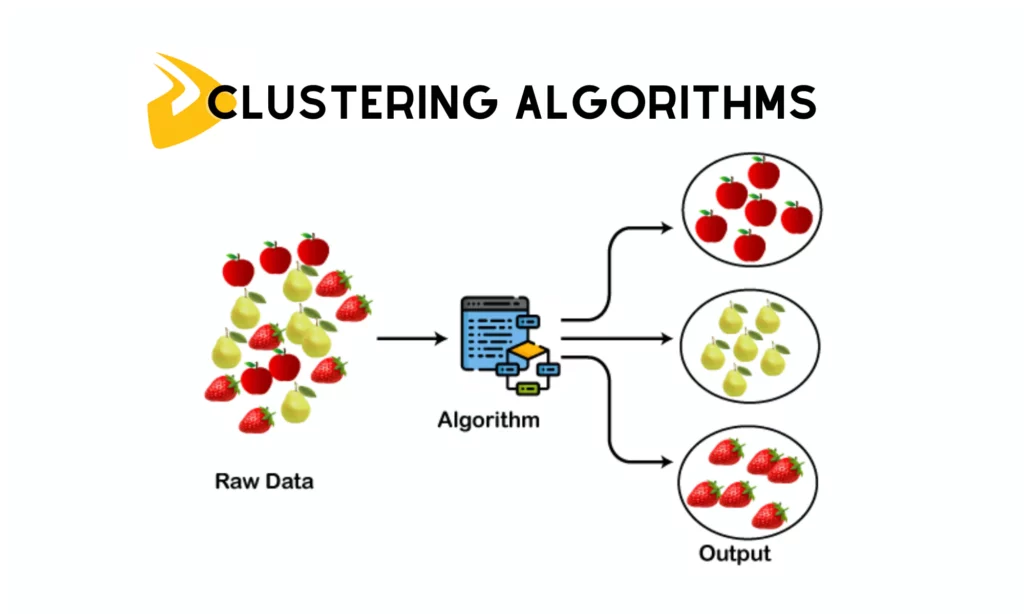
These are a type of unsupervised machine learning algorithms. This type is often used to group a set of data points or objects into clusters. It depends on inherent data patterns or structures instead of using labeled data. This turns it into a powerful tool for exploratory data analytics. There are several clustering algorithms for customer segmentation:
- K-Means Clustering: This divides customers into K different clusters based on their similarities. It’s not suitable for segmentation involving complex, varying customer behaviors.
- Hierarchical Clustering: This builds a hierarchy of clusters by merging smaller clusters (data points) into larger ones (Agglomerative) or splitting one large cluster into smaller ones (Divisive). Use this algorithm when you want to work with small or medium-sized datasets, understand nested structures, or discover customer relationships across various levels.
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise): This helps identify core customer segments based on their similarities while still discovering outlier customers who have significantly different behaviors. This method is useful when your customer data has varying shapes or densities or when you need to discover noise.
- Gaussian Mixture Model (GMM): This assumes that the dataset includes various clusters. Each cluster might be modeled by a Gaussian (normal) distribution with its own mean and variance. Further, GMM offers a probability at which a data point belongs to a cluster. This is different from K-Means Clustering, which assigns each point to a single cluster. For instance, a customer can have a 20% probability of belonging to Group A (e.g., buying high-end electronics) and an 80% probability of belonging to Group B (e.g., purchasing budget-friendly household items). Therefore, GMM is a good option if clusters overlap and have different shapes.
2. Classification Algorithms
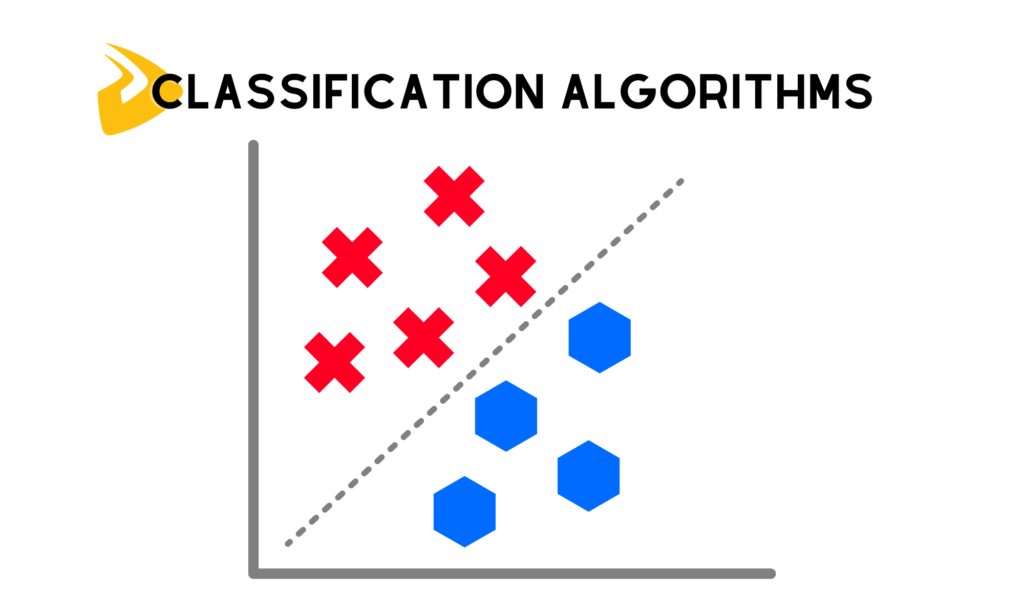
These algorithms split data points (in this case, customers) into predefined groups based on their attributes. They form the target customer segments that are already known. This differs from clustering algorithms which work without prior knowledge of the customer groups. Below are some classification algorithms for customer segmentation:
- Decision Trees: It’s a tree-like flowchart where each node represents a decision point based on a customer’s characteristics (like age or buying behaviors). It evaluates particular conditions at each step to divide customers into smaller groups. For example, a decision tree starts with a root node (“a decision point”) like whether a customer follows a vegetarian diet. Customers are divided into branches based on their answers (e.g., “Yes” or “No”). For this reason, decision trees are ideal for small to medium databases where customer characteristics show clear patterns.
- Random Forest: This method builds various decision trees (therefore called the “forest”) and combines their outcomes to enhance the accuracy of customer segmentation. It works well with large, complex databases and is useful when multiple customer attributes are involved and their interactions need to be considered.
- Support Vector Machines (SVM): This finds the optimal boundary (or “hyperplane”) that clearly distinguishes and separates customer groups based on their attributes. It’s best suited for small and medium databases, especially those with high-dimensional data (multiple features). This method also proves useful when your data is complex and non-linear, and you want an accurate decision boundary to classify customer groups.
- Logistic Regression (LR): This divides customers into one of two (binary) or more (multiclass) predefined categories based on characteristics. Particularly, it uses Sigmoid – a mathematical function – to estimate the probability at which a customer belongs to a certain group. This algorithm works well when you have well-established customer groups and simple, linear segmentation problems.
3. Neural Networks & Deep Learning
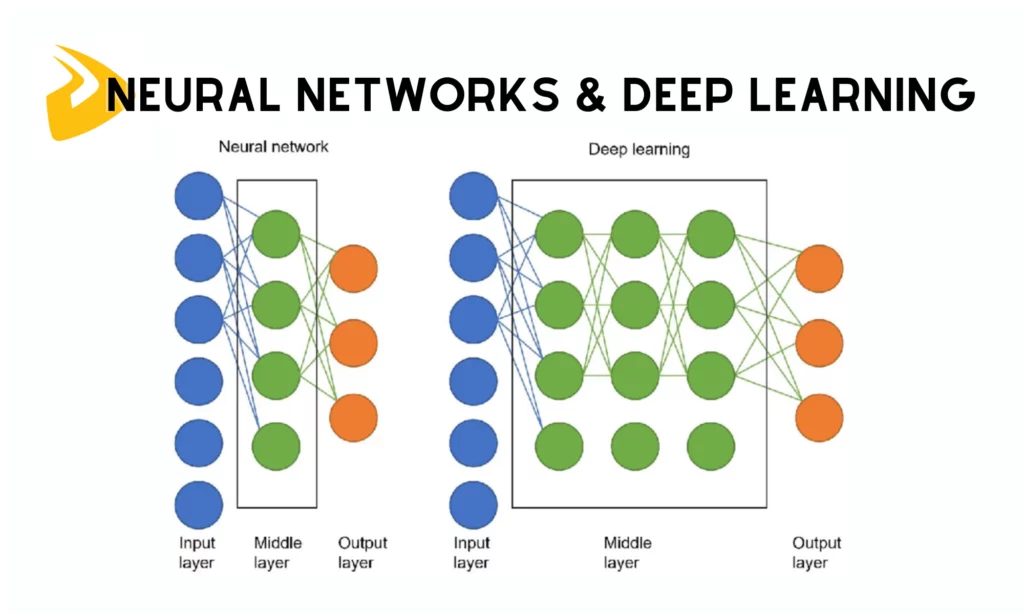
These are advanced ML algorithms that can sift through highly complex, large, and non-linear datasets to identify intricate patterns. Here are some typical algorithms for customer segmentation:
- Self-Organizing Maps (SOMs): This is an unsupervised neural network. It maps high-dimensional data points in a grid (a lower-dimensional space often represented in the 2D format). Customers with similar attributes or behaviors are located closer to each other on the grid. This algorithm helps you better visualize how different customer groups relate to each other. However, don’t use it if you want to process very large datasets.
- Autoencoders: This is a deep-learning neural network. It includes two key parts: the encoder (compressing high-dimensional data into a lower-dimensional form) and the decoder (rebuilding the original data from the compressed form). This algorithm makes your customer data less complex while capturing important features. So, it’s ideal for digging into vast, complex datasets to identify hidden patterns.
- Deep Neural Networks (DNNs): DNNs have numerous layers of neurons to interpret complex relationships between inputs (customer data) and outputs (customer groups). So, they’re suitable for processing large-scale and non-linear data.
4. Dimensionality Reduction Algorithms
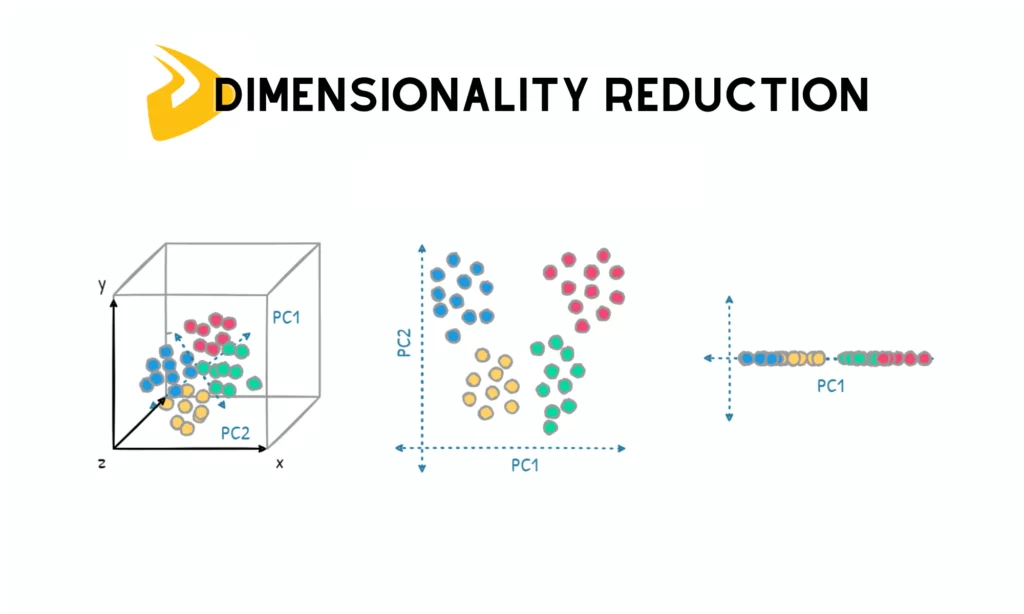
These algorithms help simplify large and complex databases by decreasing the number of variables while keeping important data. Below are two common dimensionality reduction algorithms:
- Principal Component Analysis (PCA): This statistical technique transforms your original data into a smaller set of principle components that preserve the most crucial information (variance). Meanwhile, it removes less important details, hence reducing the number of dimensions in the dataset. This makes it easier to group customers into meaningful segments.
- Linear Discriminant Analysis (LDA): This technique maps customer data into a lower-dimensional grid that maximizes the differences between labeled customer segments (like loyal customers and new customers). This helps reduce variables, making classification more effective.
- Independent Component Analysis (ICA): This method identifies independent or hidden factors in the data derived from a mixture of sources (e.g., different customer preferences). These components, albeit not obvious, can greatly influence customer segmentation. For this reason, ICA is often used when your data is noisy or when you suspect that some independent components (like buying motivations) are driving customer behaviors.
5. Association Rule Learning
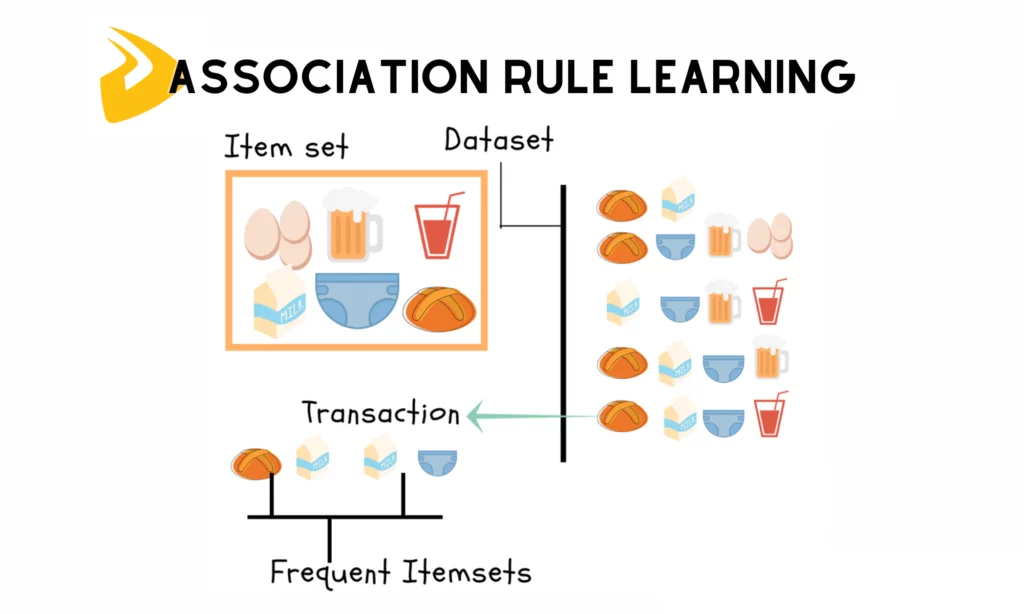
These algorithms are often used to identify interesting patterns, relationships, or rules in data. In customer segmentation, they help find how customer behaviors or preferences are related to each other. This then allows machine learning to cluster customers with similar characteristics. There are several algorithms used for this purpose:
- Apriori Algorithm: This algorithm can scan customer data to recognize which items (or sets of items) frequently appear together and generate association rules from these sets. These rules define the probability at which a customer buying one item will buy another. For instance, Apriori discovered that customers who purchase milk often order cookies. It would draw a rule suggesting that those buying milk are 80% likely to buy cookies. These patterns help group customers who regularly buy milk and cookies together for relevant marketing strategies.
- Eclat Algorithm: Eclat is also used to find frequent item sets in large databases. However, Eclat doesn’t analyze customer transactions horizontally like the way Apriori does. Rather, this algorithm turns the data into a vertical representation where each item is related to a list of transaction IDs (TIDs). For instance, if milk appears in Transactions 2, 4, and 6, the vertical list for milk would be {2, 4, 6}. Then, Eclat uses set intersections to find which transactions overlap with the TID lists. Imagine milk’s TID list is {2, 4, 6} and cookie’s TID list is {1, 2, 5}. This means milk and cookies were bought together in Transaction 1.
Applications of Customer Segmentation Using Machine Learning

With different machine learning algorithms, you can conduct customer segmentation for many purposes. Here are several outstanding applications of ML-based customer classification:
1. Targeted Marketing Campaigns
By analyzing customer data, machine learning can identify certain segments based on their behaviors, interests, or past interactions. Your company can then deliver personalized offers, ads, or emails to the right audience. This increases engagement and boosts the likelihood of converting leads into loyal customers.
2. Product Development & Customization
ML can analyze customer feedback, usage patterns, and preferences to understand a customer group’s specific needs better. This allows your company to improve product development to meet what target customers truly want.
3. Customer Support & Service Optimization
Machine learning allows for customer segmentation based on their service needs, hence boosting customer support. For instance, it can group those who often need help with similar problems. This helps your support teams provide tailored solutions or proactively resolve common issues. For this reason, your company can speed up resolution times and enhance customer satisfaction.
4. Risk Assessment & Fraud Detection
ML can identify high-risk customers who are likely to commit fraud or engage in unusual spending patterns. Particularly, ML would analyze customer behavior patterns and classify customers based on their risk levels. It then flags high-risk customers for further investigation or preventive action.
Why Should You Use Machine Learning for Customer Segmentation?

These applications of machine learning in customer segmentation give us a glimpse of its huge potential. But is this really better than traditional approaches? The answer is yes. Let’s find it out why:
More Accurate Segmentation
Traditional segmentation often depends on basic data like age, location, or income. Not to mention that customer databases are sometimes noisy and unorganized, which prevents human agents from sifting through the data to capture key information. As a result, segmented groups can contain errors or miss important customer traits, hence resulting in ineffective resource allocation and marketing campaigns.
Machine learning, by contrast, goes deeper. It analyzes different data sources – albeit scattered, mixed, or unorganized – to create more accurate and meaningful categories. This allows you to better understand your customer and devise strategies that match their needs while avoiding human errors.
Real-Time Adaptability
Look at these facts: markets shift fast and customer behaviors and needs can change quickly; meanwhile, customer interactions occur daily across different channels. All these events can generate new, large amounts of data that traditional methods may struggle to handle promptly.
However, machine learning can adapt in real-time. It constantly updates and learns from new data. This means machine learning can modify customer segments when behaviors change. This enables your company to make data-driven decisions instantly and avoid outdated customer insights that can deter your business growth.
Enhanced Customer Targeting & Personalization
As already mentioned, traditional approaches often depend on basic factors and might not consider the complexity of customer behaviors. So, they only segment customers into general groups that can overlook customer differences or hidden factors. For this reason, you can miss out on meaningful insights that lead to personalized marketing.
Machine learning, however, easily targets customers with a high level of accuracy. It does so by analyzing vast databases and diverse factors to cluster customers. This allows you to engage each customer group with relevant, personalized marketing content – be it offers, ads, or messages. As a result, you can distribute resources (i.e., human workforce or budgets) more effectively to implement successful campaigns and bring the highest benefits.
Improved Customer Retention & Satisfaction
With machine learning, your company can identify which customers are at risk of leaving and what they want to stay loyal to. You then can categorize these customers into specific segments and proactively provide tailored solutions or incentives. This helps enhance customer satisfaction, mitigate churn, and build stronger customer relationships.
Considerations Before Using Machine Learning

Despite its potential benefits, ML-based customer segmentation still has challenges you should consider.
Data Privacy & Ethical Concerns
When using machine learning, data privacy is always a big concern. This cutting-edge technology needs to collect and analyze vast volumes of customer data. This data might involve personal information, buying behaviors, or online habits.
There’s also sensitive or confidential data that customers don’t want to share with your business due to ethical concerns. They’re not sure whether their data is handled correctly and responsibly. Not to mention that you must confront financial and legal penalties if your ML models don’t work in compliance with privacy regulations like GDPR.
So, ensure your stringent adherence to these standards. Ask customers for their consent to data usage and let them know how your business will gather and use their data. This makes customers feel more confident and fosters trust in your brand.
Model Accuracy & Bias Issues
We already said that machine learning helps segment customers more precisely. This is true, but only if it’s with unbiased, high-quality, and available data. When your database contains bias or your model isn’t trained properly, machine learning can generate flawed outcomes like unfair customer segmentation.
Therefore, you need to ensure the quality and availability of training datasets used for ML models. It’s essential to frequently assess your models and review their outputs for accuracy.
Continuous Model Monitoring & Updates
Albeit intelligent, machine learning models aren’t a one-time solution. They can malfunction due to outdated technologies or unexpected defects. This prevents them from updating or catching up with ever-changing customer behaviors or market shifts. Therefore, regularly updating your model is a must to ensure that it can continue to deliver accurate and useful insights, and stay relevant with data changes. Without this, customer segmentation may become outdated and less effective.
5 Key Steps to Implement Customer Segmentation Using Machine Learning

If you want to implement machine learning-based customer segmentation effectively, you should follow a well-structured guide that includes the following five key steps:
Step 1: Collect & Prepare Data
Data is the backbone of any ML model. Therefore, the first step in segmenting customers using machine learning is collecting and preparing data.
Start by gathering the raw material. This includes demographics, purchase behaviors, customer interactions, and browsing history that come from different sources.
When you have the data, clean and preprocess it. This might involve correcting errors, handling missing values, and removing any outliers that can ruin the outputs. For instance, for incomplete customer information, you’ll need to remove those inputs or fill in the gaps. By cleaning data, you can ensure that your model will work well and produce accurate outcomes.
Next, identify which customer data points are relevant to your ML model. These data points, or known as “features”, are individual measurable characteristics of the data that help the model understand patterns and make decisions. You can adjust existing features or create new ones through feature engineering. As more relevant features can lead to more accurate segmentation, focus on features that can uncover meaningful patterns and improve the model’s performance.
Step 2: Choose the Right Algorithms & Tools
Once you’ve done with data collection and preparation, it’s time to choose the right machine-learning algorithms and tools for customer segmentation.
When selecting algorithms, you need to consider several following factors. First, think about the type of data you have as different algorithms work best with different data types. If your data is mostly numerical, opt for K-Means or Gaussian Mixture. Meanwhile, Random Forests or Autoencoders could be good options for large-scale, complex datasets.
Second, consider which output you want to receive. If you’re looking for clear and distinct customer groups, choose clustering algorithms like K-Means or DBSCAN. Meanwhile, classification algorithms like Decision Trees or Logistic Regression might be ideal for dividing customers into predefined categories.
To run these algorithms, you can’t ignore machine learning tools or platforms. Python libraries (e.g., TensorFlow or scikit-learn) are common technologies that help develop ML models. In case your team lacks technical expertise in this realm, we advise you to leverage ready-to-use services like Amazon SageMaker and Microsoft Azure. These services help you conduct ML-based customer segmentation without the need to code from scratch.
If you want to build a customized, scalable ML model, outsource the development project to a trusted company. Here at Designveloper, our team has extensive expertise and experience in crafting cutting-edge AI solutions tailored to your specific business needs.
Leveraging the latest AI advancements and advanced algorithms, we’re committed to creating dynamic and innovative models that seamlessly integrate your existing infrastructure and offer robust security practices. These solutions boost your operational efficiency, enhance customer experience, and propel your business growth. Contact us here!
Step 3: Train the Model
Once you’ve chosen the right algorithms and tools, the next step is to train your model. Begin by dividing your data into two groups: the training data and the testing data. The training group teaches your model to recognize patterns, while the testing group assesses how well the model works on unseen data.
Then, you’ll feed the training data into the model where algorithms continue to handle customer characteristics like demographics or purchase behaviors. Here, the model tries to figure out patterns and generate meaningful customer segments based on these attributes.
Step 4: Evaluate the Model
Upon training, you should use the testing data set to evaluate the model’s performance. Accordingly, you can conduct thorough assessments through the following metrics:
- Accuracy: Consider how precisely the model segments customers into categories.
- Precision and Recall: Measure how correctly the model identifies specific segments.
- Silhouette Score: Evaluate how well customers fit into their assigned groups compared to other groups.
- Adjusted Rand Index (ARI): Compare the clustering performance with ground truth (if available).
If the model doesn’t function well, you can fine-tune hyperparameters. These hyperparameters are settings that monitor how algorithms work; for example, a hyperparameter can be the number of clusters in K-Means Clustering. Tuning hyperparameters is an iterative process where you modify these parameters, retrain the model, and assess the results. It might need various attempts to find the best settings that enhance model performance.
If the model still underperforms, you may need to collect more data, improve data quality, and try different algorithms to achieve better outcomes.
Step 5: Interpret Segmentation Results
Interpreting segmentation results is crucial to creating appropriate, customized marketing strategies for your business. Begin by analyzing the customer segments created by your model. Look closely at which patterns or trends appear in each segment. This analysis helps you understand the unique behaviors and interests of your customers.
Then, learn about the key attributes of each group, like demographics or buying habits. These characteristics give deep insights into what makes each segment different, hence tailoring your marketing strategies more effectively.
You can use visualization techniques like dendrograms or scatter plots to display your segmentation results clearly. Dendrograms can show how closely different customer groups are related, while scatter plots illustrate how different groups relate to each other based on particular factors. Visualization helps everyone involved understand the insights from the segmentation process, support marketing personalization, and enhance data-driven decision-making.
Conclusion
Now, you’ve completed the journey of exploring customer segmentation using machine learning. From common algorithms and applications of ML-based classification to detailed steps to implement segmentation effectively, we expect you to leverage these insights to drive more targeted marketing campaigns. Continue discovering the latest advancements in ML and data science to stay ahead of the curve and fine-tune your segmentation strategies. For more interesting information about this topic, subscribe to our blog!
Also published on

Share post on
























